Data Pipeline: Logic and Data Process
Data Process
Data processes are data pipelines created and run in LOC and are consisted of logic. You can browse them in Explorer (using the project hierarchy) or Flat Search View (as a list).
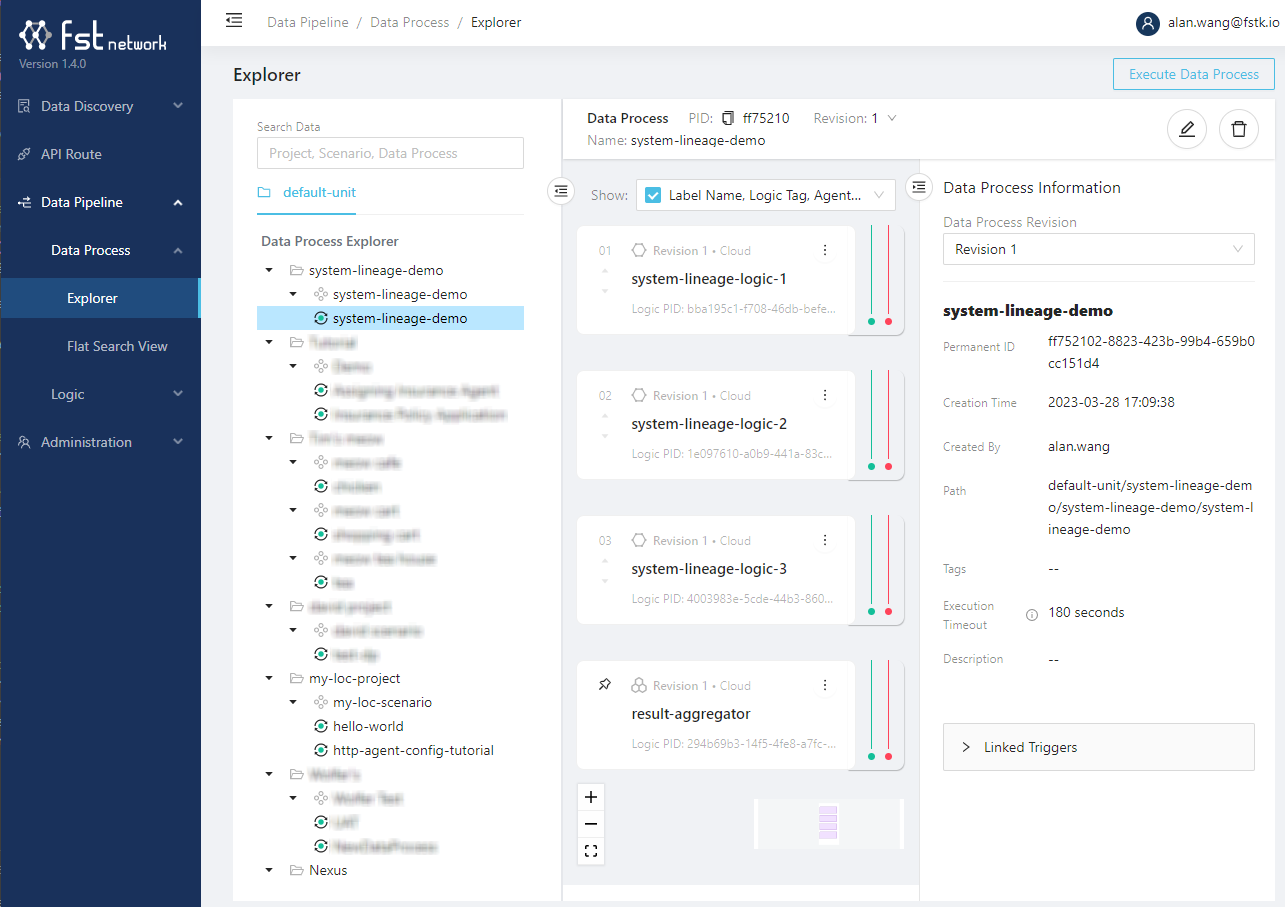
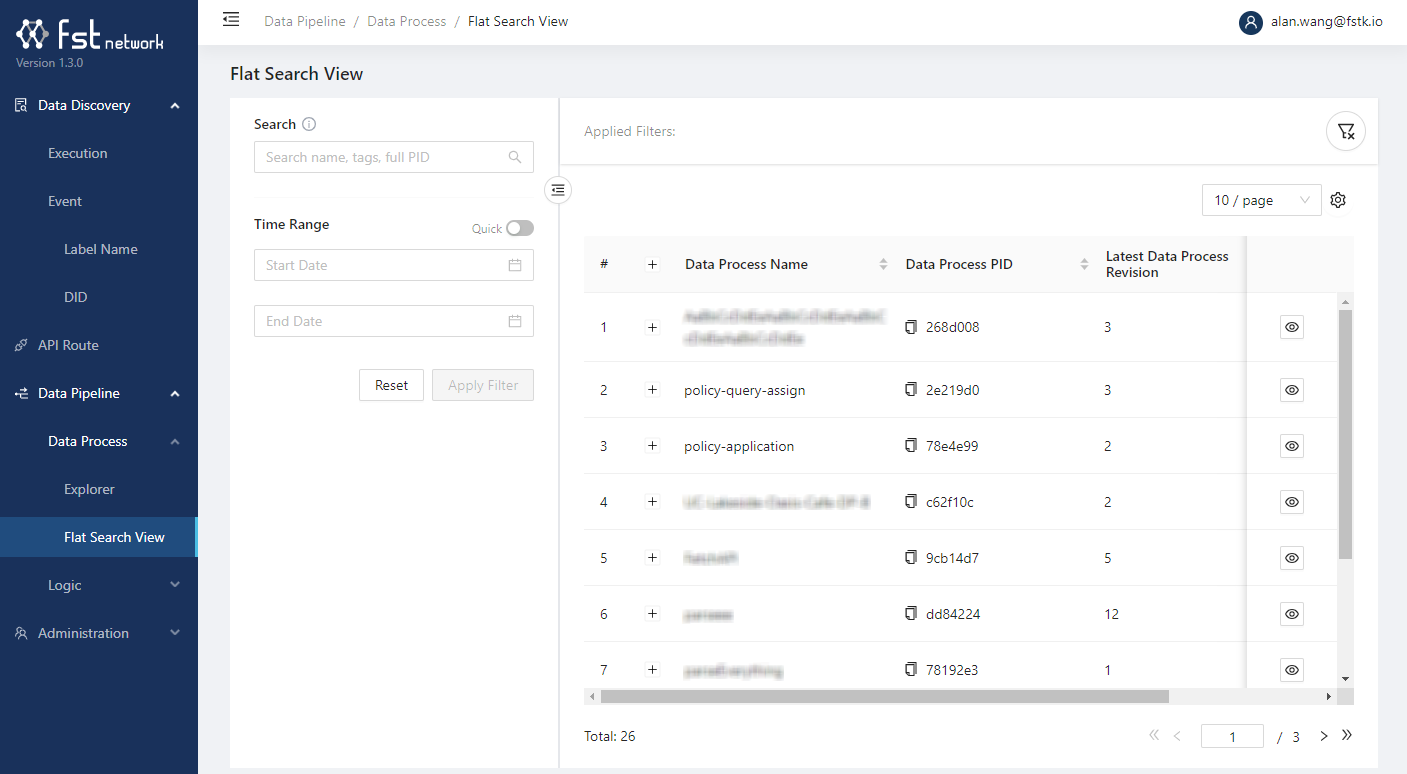
A data process is "deployed" once it was created. It would only be executed either invoked by triggers or to be run manually.
Modifying an existing data process creates a new revision.
You can delete a data process even though some logic are already linked to it.
A logic, after being linked into a data process, can setup its own agent configuration and logic variable. If a referenced agent configuration has been deleted (missing), LOC will prevent you from executing the data process until the missing agent configuration is removed or fixed.
Logic
Logic are code modules to be linked into one or more data processes.
Depends on how and where the logic are created, there are two types of logic can be browsed: cloud logic and native logic. Only cloud logic are editable in Studio.
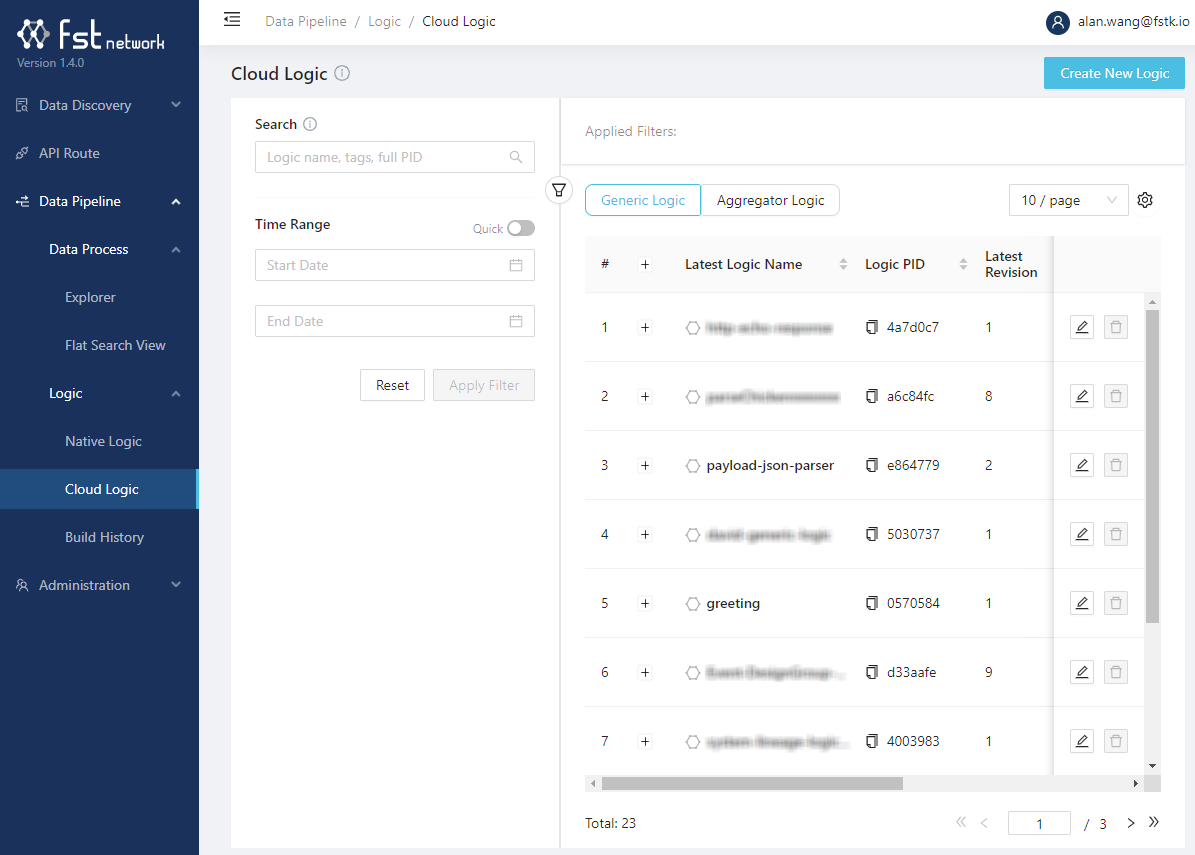
You can view the logic code (all its revisions and draft) by clicking the logic name:
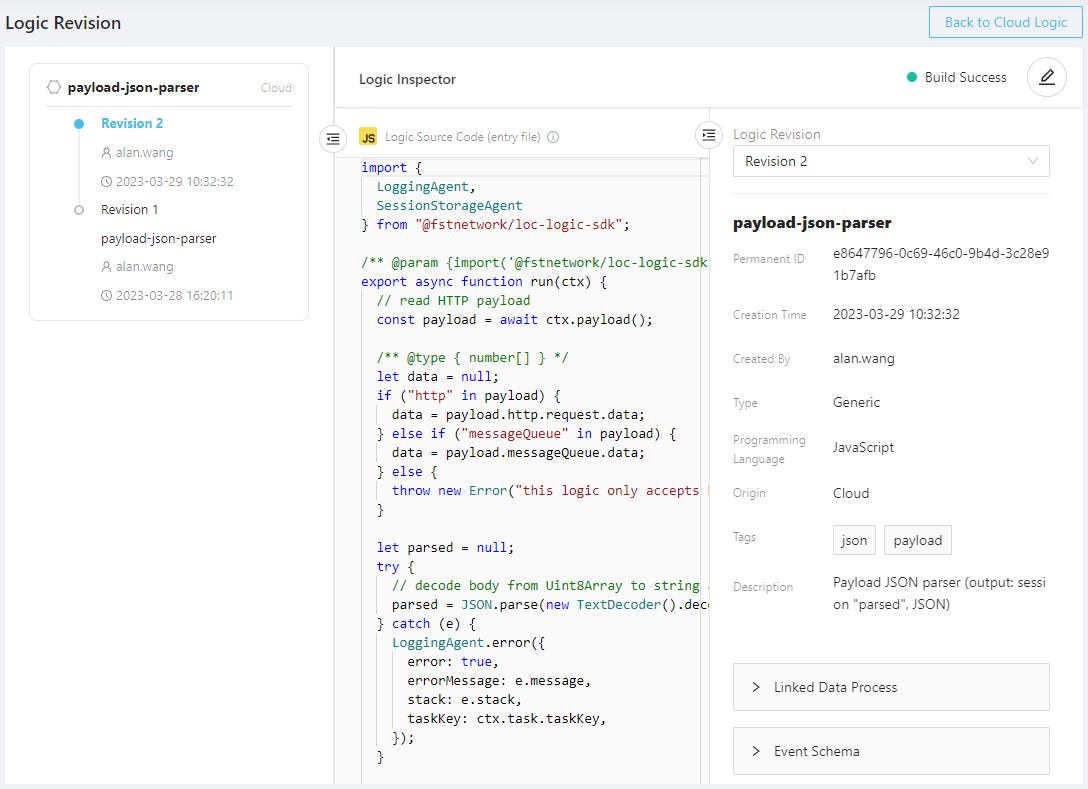
The saved edited code of a logic before build is referred as the draft. You can create draft from any previous revisions.
You can save the draft by clicking the "✓" icon, or click the rocket (🚀) icon to build it:

If the logic did not compiled successfully, you can instect the error log:

A logic is "deployed" once it was created. It has to be linked into a data process to be executed with it.
A logic cannot be deleted if it is linked to any data process.
Modifying an existing cloud logic or uploading a modified logic from CLI (native logic) creates a new revision.
You can add agent configuration and logic variables to a linked logic.
Build History
The logic build history is the log of building/compiling status of all cloud logic:
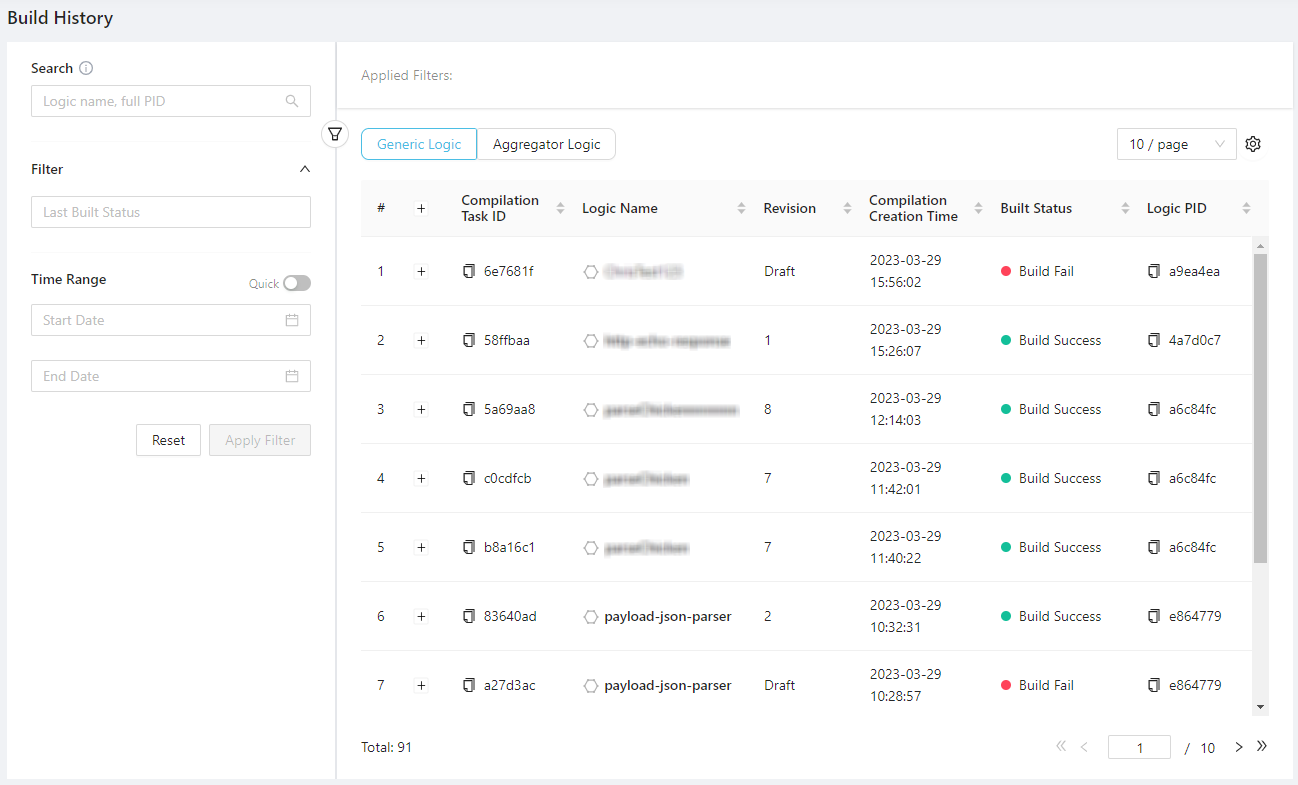
The build logs of deleted logic (displayed in non-bold names) won't be removed.